A Fast Method to Bulk Insert a Pandas DataFrame into Postgres
Aug 8, 2020 · 774 words · 4 minutes read
There can be times when you want to write a Pandas DataFrame directly to a database without writing to disk. Unfortunately the default methods in Pandas are slow. In this post I compare several methods for inserting the DataFrame into a Postgres database – skip here to see the fastest.
Dataset
For this post, the dataset is daily stock quotes for companies in the S&P500 for the period of 1998 through July 31st, 2013.
The dataset contains 1,808,278 records of the date, time (always 0), open, close, high, low, volume, and ticker symbol.
The destination Postgres table schema is defined by:
CREATE TABLE IF NOT EXISTS public.dest (
date TIMESTAMP,
time INT,
open NUMERIC,
high NUMERIC,
low NUMERIC,
close NUMERIC,
volume NUMERIC,
ticker TEXT
);You can see most fields are numbers (NUMERIC or INT) but there is also the date column (TIMESTAMP) and the ticker symbol (TEXT).
Timing
The timing of each method was measured using timeit.repeat and taking the minimum time, which should be a good estimate of the fastest the code can execute.
Variability in timing is attributed to other processes running in the background on the system.
In order to measure fairly I included processing steps specific to each implementation in the timing.
The built-in DataFrame.to_sql method has no additional processing but the psycopg2 methods do (converting to a list of dictionaries or string buffer).
Method specific processing timing could be measured separately from the insert but this way each approach is starting from the same place – a processed DataFrame that is ready to be inserted into the database.
Cleanup
Before each iteration of timeit.repeat I run setup code to TRUNCATE the table.
This set is excluded from timing.
pandas.DataFrame.to_sql
If you’re looking to insert a Pandas DataFrame into a database, the to_sql method is likely the first thing you think of.
Simply call the to_sql method on your DataFrame (e.g. df.to_sql), give the name of the destination table (dest), and provide a SQLAlchemy engine (engine).
If the table already exists (this one does) then tell Pandas to append, rather than fail, (if_exists="append").
df.to_sql(
name="dest",
con=engine,
if_exists="append",
index=False
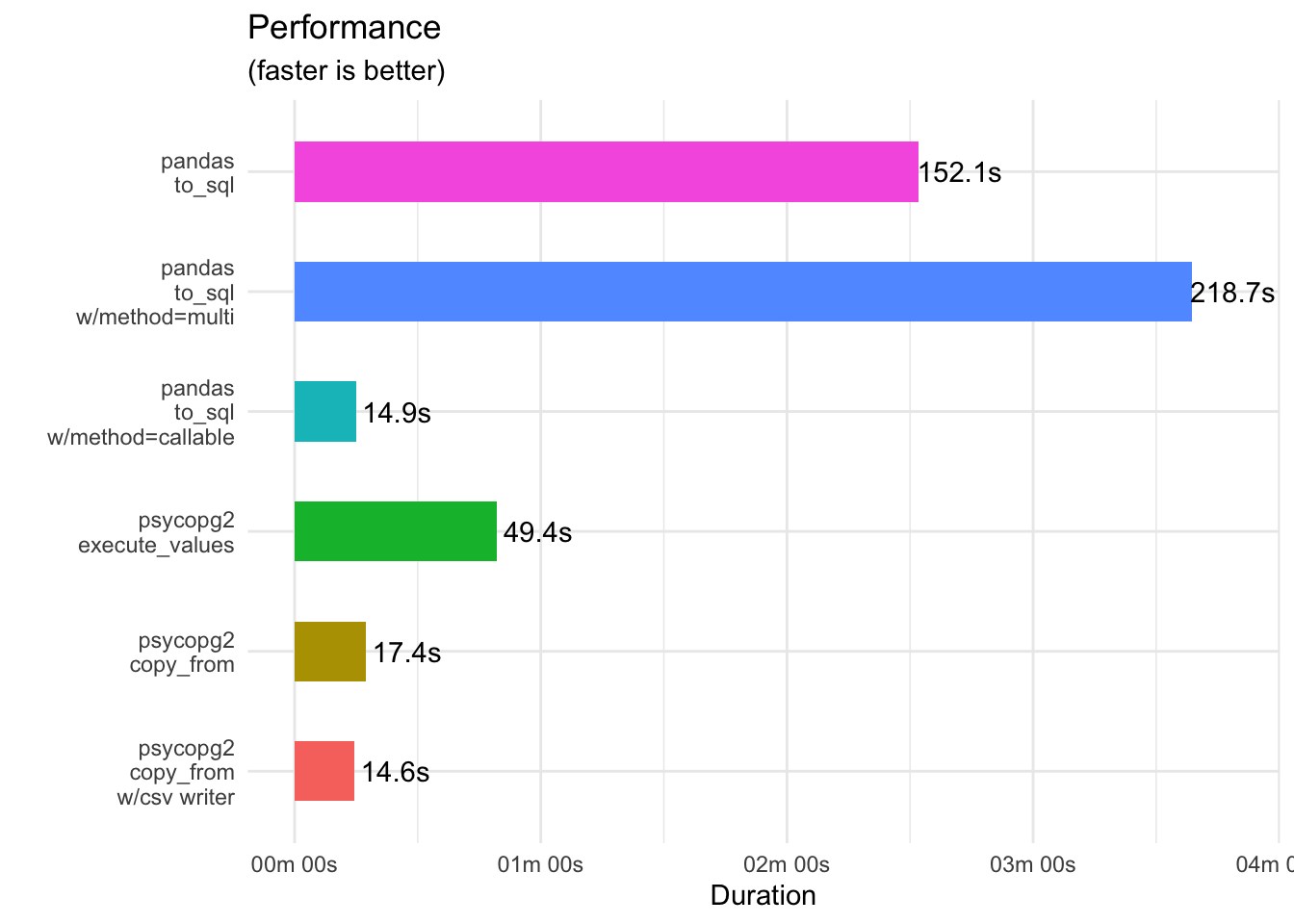
)This, however, is painfully slow. On my system, the best time was 142.67s (2min 22s).
pandas.DataFrame.to_sql with method="multi"
Given that you tried the previous approach and were unsatisfied, you might dig into the documentation looking for options that may improve performance.
One choice is to set method="multi" which will insert multiple records at a time in a singe INSERT statement — i.e. perform a batch insert.
df.to_sql(
name="dest",
con=engine,
if_exists="append",
index=False,
method="multi"
)This actually performs worse than the default method!
The best time was 196.56s (3min 17s).
pandas.DataFrame.to_sql with method=callable
Another choice is to set method to a callable function with signature (pd_table, conn, keys, data_iter). The Pandas documentation shows an example of a callable that uses the Postgres COPY statement.
def psql_insert_copy(table, conn, keys, data_iter):
"""
Execute SQL statement inserting data
Parameters
----------
table : pandas.io.sql.SQLTable
conn : sqlalchemy.engine.Engine or sqlalchemy.engine.Connection
keys : list of str
Column names
data_iter : Iterable that iterates the values to be inserted
"""
# gets a DBAPI connection that can provide a cursor
dbapi_conn = conn.connection
with dbapi_conn.cursor() as cur:
s_buf = StringIO()
writer = csv.writer(s_buf)
writer.writerows(data_iter)
s_buf.seek(0)
columns = ', '.join('"{}"'.format(k) for k in keys)
if table.schema:
table_name = '{}.{}'.format(table.schema, table.name)
else:
table_name = table.name
sql = 'COPY {} ({}) FROM STDIN WITH CSV'.format(
table_name, columns)
cur.copy_expert(sql=sql, file=s_buf)
df.to_sql(
name="dest",
con=engine,
if_exists="append",
index=False,
method=psql_insert_copy
)This improves performance quite a bit.
The best time was 14.83s.
psycopg2 using execute_values
Another option is to use the psycopg2 module instead of SQLAlchemy. Similarly to the to_sql method=multi, the psycopg2 module provides the execute_values function which performs bulk inserts into the database. However we have to convert the DataFrame into another format (e.g. a list of dictionaries).
with conn.cursor() as c:
execute_values(
cur=c,
sql="""
INSERT INTO dest
(date, time, open, high, low, close, volume, ticker)
VALUES %s;
""",
argslist=df.to_dict(orient="records"),
template="""
(
%(date)s, %(time)s, %(open)s,
%(high)s, %(low)s, %(close)s,
%(volume)s, %(ticker)s
)
"""
)
conn.commit()Despite converting the DataFrame, this method is still pretty fast – the best time was 46.86s. Yet there’s other options too.
psycopg2 using copy_from and a string buffer
This next approach uses the psycopg2 copy_from function to
sio = StringIO()
sio.write(df.to_csv(index=None, header=None))
sio.seek(0)
with conn.cursor() as c:
c.copy_from(
file=sio,
table="dest",
columns=[
"date",
"time",
"open",
"high",
"low",
"close",
"volume",
"ticker"
],
sep=","
)
conn.commit()17.33s
psycopg2 using copy_from and csv
This final approach
sio = StringIO()
writer = csv.writer(sio)
writer.writerows(df.values)
sio.seek(0)
with conn.cursor() as c:
c.copy_from(
file=sio,
table="dest",
columns=[
"date",
"time",
"open",
"high",
"low",
"close",
"volume",
"ticker"
],
sep=","
)
conn.commit()Results